
HySTER: A Hybrid Spatio-Temporal Event Reasoner
Published in Thirty- Fifth AAAI Conference on Artificial Intelligence Workshop on Hybrid Artificial Intelligence, 2021
Neuro-Symbolic Video Question Answering
During my MSc in AI and ML at Imperial College London, I explored the task of video understanding through the proxy task of Video Question Answering (VideoQA). My objective was to investiagte ways to equip an AI model with visual reasoning abilities: perception, and causal and temporal reasoning.
The VideoQA task I selected was that from the CLEVRER: Collision Events for Video Representation and Reasoning dataset; developed by the MIT-Watson Lab. The dataset is composed of videos exhibiting motion and collision between objects on a constant background, whilst the questions require causal and temporal reasoning to be answered.
I held this research under the supervision of Professor Alessandra Russo and Nuri Cingillioglu, with whom I will be sharing my work as a full paper and oral presentation in the Thirty-Fifth AAAI Conference Workshop on Hybrid Artificial Intelligence. Our the paper is available online.
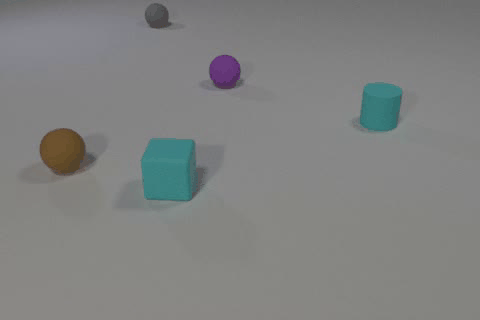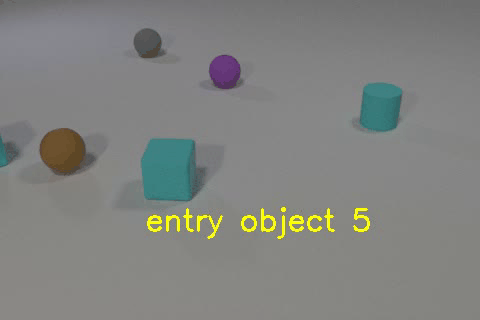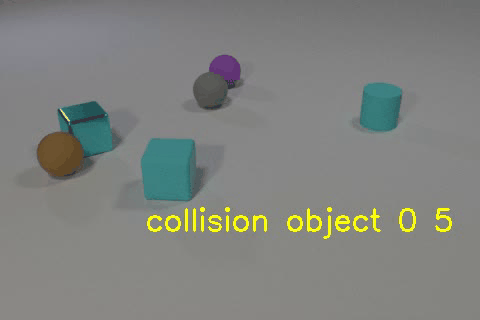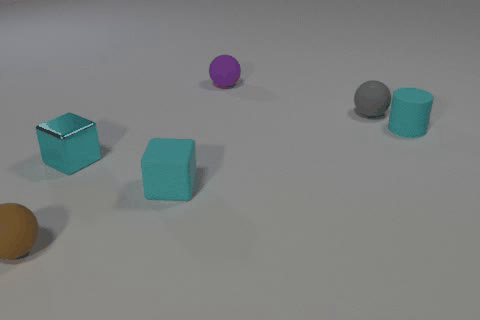
Video of the CLEVRER dataset annotated by our model. The object descriptions and events are extracted from the model’s reasoning.
Summary
We developed a neuro-symbolic framework for the task of VideoQA, named the HySTER: Hybrid Spatio-Temporal Event Reasoner, which we tested on the CLEVRER datatset.
Our model leverage the strength of deep learning through Mask R-CNN and ResNets in order to extract information from low-level video frames and ground a symbolic representation of the objects along with their position in the scene. The symbolic component, implemented under the form of Answer Set Programming (ASP) using clingo, then performs temporal and causal reasoning over the reconstructed scene, detecting the events occurring and answering the questions.
Methodology
An overview of the overall framework is presented in the following figure, and comprises three main components.
- Video Parser: detects, classifies and localises the objects in the scene. This infromation is then translated into a symbolic representation.
- Question Parser: translates the natural language questions into logic queries.
- Symbolic Reasoner: detects events from the abstract scene representation built by the Video Parser, and reasons over them to answer the queries.
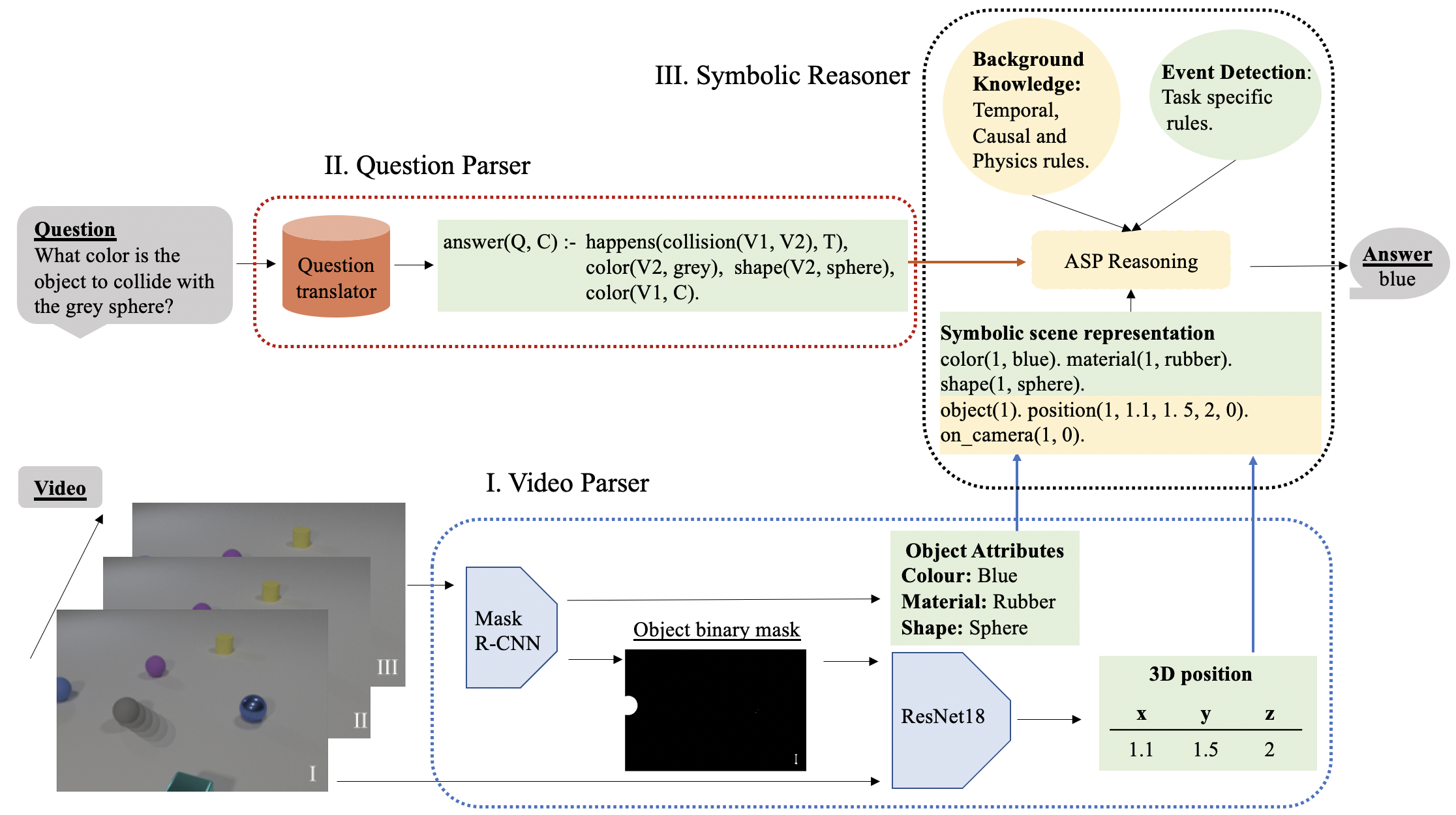
Overview of the model architecture composed of 3 main components: I. Video Parser, II. Question Parser, III. Symbolic Reasoner. The yellow shaded parts refer to general components transferable between tasks. The green shaded parts refer to task specific symbolic components and information.
Results
Find the results on the CLEVRER challenge leaderboard , under the label TS_NS_IMPERIAL, where we outperfromed the baselines set in the CLEVRER paper.
(Please note that the results in the leaderboard correspond to our best overall score, not the best performance in each question type, hence the difference with the values in our paper).
Next Steps
In the SPIKE research group, we aim to explore the potential of using inductive logic programming and ![]() to reduce the amount of the human engineering in the process, allowing the model to learn event detection rules directly from abstract scene representations and question-answer pairs. Please contact me for details concerning our symbolic rule learning methodology and initial results.
to reduce the amount of the human engineering in the process, allowing the model to learn event detection rules directly from abstract scene representations and question-answer pairs. Please contact me for details concerning our symbolic rule learning methodology and initial results.